
Let's revive an old but significant subject, transcribed in a blog by Slawomir Walkowski, a Software Engineer at Google Cloud. In this post, we delve into building idempotent functions to enhance the resiliency of your serverless systems.
Unveiling Idempotent Functions
In computer science, idempotence guarantees that a function will yield consistent results - no matter how many times you execute it. When executing a function multiple times for a specific event, the resulting outcome stays the same, only then do we say the function is idempotent.
The crux of idempotent functions lies in the retry aspect. When a function fails, we might need to retry it to ensure correct behavior. However, the challenge appears if the re-execution generates undesired results or side effects. This is where building the function to be idempotent saves the day.
Let's clarify this idea with an example, a simple data processing function that writes results to two separate storage systems. Do you anticipate the problem here? What if the upload fails in one of the storages? As a quick solution, you may retry the function. It will certainly save the data to the second storage system (provided the upload is successful), but it will also duplicate the record into the first storage system, leading to potential inconsistencies.
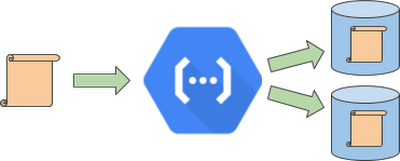
How do we circumvent this? Let’s dive deeper.
Craft Your Function with Idempotency
How about we tweak a non-idempotent function into an idempotent one? Let’s take an instance where a document is first added to Cloud Firestore and then uploaded to a separate storage system. If the upload to Cloud Firestore turns successful, but the second upload fails, retrying just doubles the same document into the Cloud Firestore. This is what we intend to avoid.
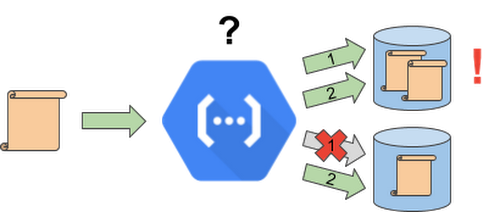
Embrace your Event IDs
A viable solution to this dilemma is using the Event ID - which uniquely identifies an event that triggers a background function. Upon using the Event ID as a document ID, and by writing document contents to Cloud Firestore, we ensure the idempotent functionality of our data storage and uploads. In simpler terms, a retried function execution doesn't add a new document, but instead, overrides the existing one with the same content. So, it prevents data duplication or leftover work. To follow this principle, you can provide the Event ID as your idempotency key in some particular APIs (e.g., Stripe).
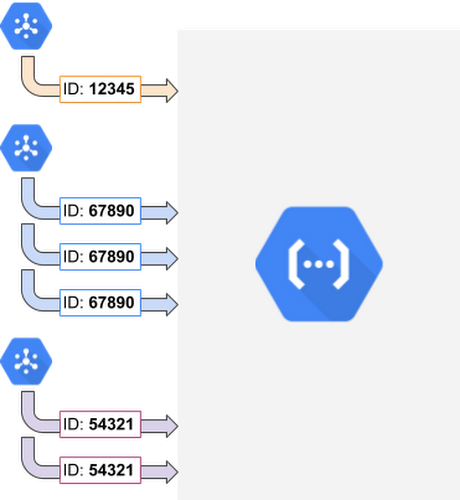
Dealing with Non-idempotent Systems
Now, what if the system you are working with doesn't support idempotency? Consider the an email delivery service. A retried function here could lead to duplicate emails. To counter this, you can mark the handled events by recording their Event ID as we already discuss. This significantly reduces the chance of unanticipated retried calls to other services. But it relies on the uniqueness and proper generation of event IDs, so you need to be confident in the service idempotence. Also, it's not suitable for operations where the same event might need to be processed in different ways under different circumstances.
Exploring the Lease Mechanism
Though the approaches mentioned above eliminate the majority of duplicated calls on function retries, there's a fringe chance of parallel retried executions happening more than once. Using a lease mechanism is a good practice here. When worked strategically, this mechanism let you carry out the non-idempotent section of the function exclusively for a specific duration.
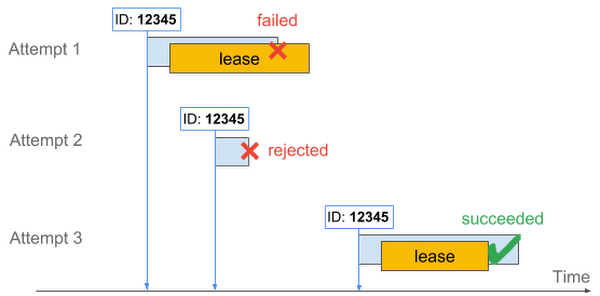
A lease mechanism involves temporarily granting a client exclusive access to a resource or operation for a specified period. During this lease period, the client can perform the operation, and other clients are prevented from doing the same operation on the same resource.
The lease has an expiration time. If the operation is not completed within this time frame, the lease expires, and other clients may acquire a new lease to attempt the operation.
How it helps with Idempotency
By using leases, the system ensures that even if the same operation is requested multiple times (e.g., due to a retry), only one instance of the operation will be processed at a time. This prevents duplicate operations.
The system keeps track of which operations have an active lease. This information can be used to determine whether a new incoming operation is a retry of an existing operation or a new operation.
If a lease expires before the operation is completed, the system can handle it in various ways. It might roll back the operation, consider it failed, or allow another client to retry.
How to implement it
- Each operation is associated with a unique key (like a transaction ID or operation ID). This key is used to acquire and check the lease.
- The lease information (key, expiration time, etc.) is typically stored in a persistent, distributed data store that is accessible by all clients and parts of the system.
- Clients can renew leases if they need more time to complete the operation. The system must handle scenarios where a client fails to renew a lease due to issues like crashes or network failures.
- The system must manage concurrent lease requests in a way that ensures consistency and prevents race conditions.
To sum up
So, when designing your serverless architecture, ensuring idempotence can dramatically increase the reliability of your setups. As we have seen, multiple methods, ranging from using event IDs to operating a lease mechanism, can help achieve idempotence.
| Factor | Lease Mechanism | Event ID as Document ID |
|---|---|---|
| Primary Function | Temporarily grants exclusive access to a resource or operation. | Uses a unique identifier for each event to prevent duplicate processing of the same event. |
| Use Cases | Ideal for long-running, stateful operations and where concurrent operations might be an issue. | Suitable for stateless operations where each event is unique and distinct. |
| Complexity | Higher complexity in implementation. Requires managing lease renewals and expirations. | Simpler to implement. Relies on the uniqueness and proper generation of event IDs. |
| Concurrency Handling | Prevents concurrent operations on the same resource by providing exclusive access. | Does not inherently handle concurrency, but prevents duplicate processing of the same event. |
| Flexibility | More flexible as it allows operations to extend their execution time by renewing the lease. | Less flexible, as operations are typically one-off and based on the uniqueness of the event ID. |
| Risk Management | Risk of resource locking if a lease is not properly released or expires. | Risk of duplicate processing if event IDs are not properly managed or generated. |
| Scalability | Can be challenging to scale due to the need for managing leases across multiple instances. | Easily scalable, as each operation is independent based on its event ID. |
| Ideal Scenarios | Best for scenarios with potential for multiple instances trying to perform the same operation. | Best for scenarios where operations are idempotent and can be identified by a unique ID. |
| Data Store Dependency | Requires a persistent, distributed data store to manage lease information. | Requires a data store where event IDs are used as keys to check for operation completion. |
If you want to go further, you can check out: